


We’re entering a golden age of engineering biology
A guest post by Joshua March and Kasia Gora



As you all know, I am a techno-optimist. The current decade truly seems like a time of marvels, with major simultaneous advances in energy technology, AI, biotech, space, and a number of other fields. But whereas I’m pretty well-equipped to understand some of those technologies, the biotech industry often feels like a completely separate world. Thus, I rely more on experts in the field to tell me what’s going on there.
Two such experts are Joshua March and Kasia Gora, founders of SCiFi Foods. Although their company does cultivated meat — which Josh wrote a Noahpinion guest post about in 2022 — they’re pretty knowledgeable about the state of the biotech industry in general. So when I was looking around for someone to write a guest post explaining why the 2020s are an exciting decade for biotech, they were a natural choice. I thought this post did a great job of summing up the importance of various disparate advances with one core concept: the transformation of biology from a scientific discipline to a field of engineering.
Financial disclosure: I have no financial interest of any kind in SCiFi Foods, and no plans to initiate one. But this post does discuss the promise of lab automation, so I should mention that I do have an investment in a company called Spaero Bio, which does lab automation.
“Where do I think the next amazing revolution is going to come? … There’s no question that digital biology is going to be it. For the very first time in our history, in human history, biology has the opportunity to be engineering, not science.”
—Jensen Huang, CEO, NVIDIA
The field of biology has driven remarkable advancements in medicine, agriculture, and industry over the last half-century, despite facing a significant hurdle: The immense complexity of biological systems makes them incredibly difficult to predict. This lack of predictability means that any innovation in biology requires many expensive trial-and-error experiments, inflating costs and slowing down progress in a wide range of applications, from drug discovery to biomanufacturing. But we are now at a critical inflection point in our ability to predict and engineer complex biological systems—transforming biology from a wet and messy science into an engineering discipline. This is being driven by the convergence of three major innovations: advancements in deep learning, significant cost reductions for collecting biological data through lab automation, and the precision editing of DNA with CRISPR.
Although we can trace the history of biology from ancient to modern times, until very recently, people have had remarkably little understanding of the mechanistic basis of life. It wasn’t until the late 18th and early 19th centuries that scientists began to understand the nature of inheritance, and it wasn’t until 1943 that we discovered DNA was the heritable material. It took another decade for James Watson, Francis Crick, and Rosalind Franklin to work out the structure of DNA and how it encodes information. Once biologists understood that DNA codes for mRNA, which codes for proteins, it suddenly became possible to start manipulating DNA for our purposes!
The biologist Herb Boyer was at the cutting edge of this field, and in 1976 he and venture capitalist Robert Swanson founded Genentech, the world’s first biotechnology company. Genentech set out to produce human growth hormone (HGH) “recombinantly” in bacteria, replacing the expensive procedure of extracting HGH from human cadavers, which had been responsible for at least one disease outbreak. The rise of Genentech met a critical medical need for safe HGH and spawned the biopharmaceutical industry, changing the trajectory of human health and medicine forever.
Today, biotech is a trillion-dollar industry, built on a foundation of 1970s recombinant DNA technology. It has been responsible for many huge wins, including the rapid development of novel mRNA vaccines to fight the COVID-19 pandemic, gene therapies against cancer, blockbuster weight loss drugs like Ozempic (already prescribed to a whopping 1.7% of the US population), and an ever-expanding pharmacopeia of drugs. And while human health applications garner the most attention, biotechnology also plays an increasingly significant role in agriculture and industrial production.
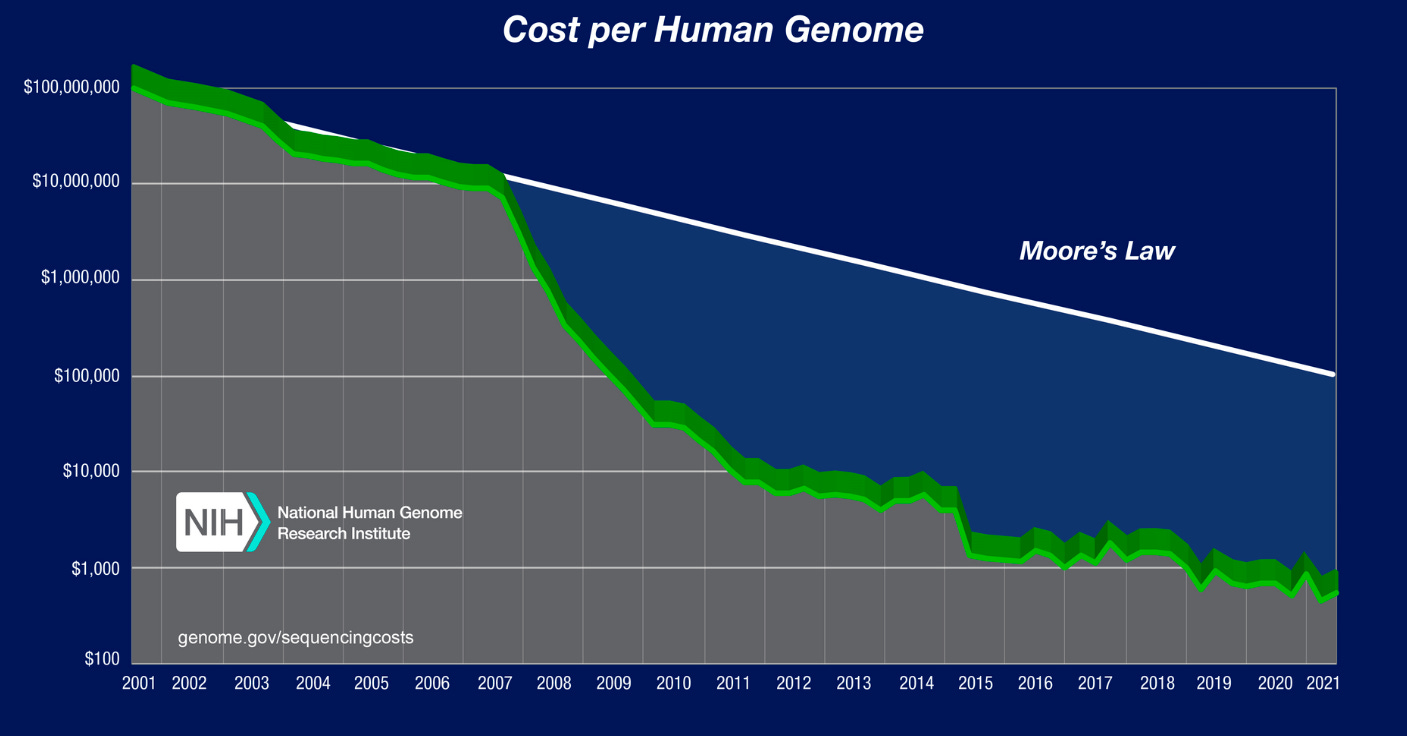
One of the most striking examples of the speed of progress in biology has been the exponentially decreasing cost of DNA sequencing. The Human Genome Project started in 1990 and took 13 years to sequence the genome of a single human, considered a wildly ambitious venture at the time, at a cost of billions of dollars. It’s worth noting this feat was also accomplished using 1970s technology, Sanger sequencing, though greatly improved through automation. By the 2000s, the aptly named next-generation sequencing (NGS) dramatically accelerated the rate of DNA sequencing while dropping the cost significantly. From the billions of the Human Genome Project to ~$1m in the mid-2000s, we can now sequence an entire human genome for ~$600, with the cost soon expected to go below $200! Because of this decreasing cost, genome sequencing is becoming much more common—just last year, the UK Biobank, one of the world's largest databases, released the complete genome sequences of half a million individuals. We’re just starting to scratch the surface of the insights this data will make possible.
The vast complexity of biology
Although we have made rapid progress in our ability to read DNA cheaply and quickly, we are still far from a comprehensive understanding of biology. For example, 20 years after the publication of the first human genome, we still don’t understand the molecular, cellular, or phenotypic function of many of our 20,000 genes, much less the complex interactions between these genes and the environment. What will happen if a particular gene mutates? What’s the impact on the cell, or the overall organism? And how can we apply all this genetic data to diagnose, treat, or prevent complex diseases like cancer, depression, or diabetes? These answers are hard to come by because biology is staggeringly complex, and this complexity is the characteristic feature of life.
Take, for instance, the complexity of a human being. Each of us is comprised of trillions of cells, each operating more or less independently. Each of those cells has its copy of the genome, encoding those 20,000 genes, about 300,000 mRNA molecules, and about 40 million proteins floating around, interacting and doing various things. It’s little wonder that we don’t have models that are predictive across the different biological modalities (from DNA > RNA > protein > trait). Unlike an engineer designing a bridge, who can apply physical laws and some basic software models to predict whether a design will work with near certainty, biologists have no choice but to do a lot of expensive and time-consuming laboratory experiments. For example, a researcher looking for the next cancer drug has to test various natural compounds against a cancer cell line, which involves being hunched over in a biosafety cabinet for 5 hours a day for months, comparing the growth of the cell lines with and without the presence of a compound. And even then, what they discover is context-dependent, and may not work on another cancer cell line, much less an actual patient!
The impact of these laborious efforts is apparent in drug development. Because of the complexity of biology and our lack of predictive power, developing new drugs is an incredibly long and expensive endeavor—about $2-3B per drug. Historically, it has been impossible to predict the efficacy of a drug molecule in a system as complex as the human body, so traditional drug development entails screening thousands of molecules in a scaled-up and automated version of that cancer cell experiment. Any drug that looks effective in screening gets tested in animals, and ultimately humans, in long and expensive clinical trials with meager success rates (10-15%) and no guarantee of treating disease and improving patient outcomes. Effective drugs often fall out of the pipeline because of unexpected toxicity, which is very difficult to predict until the molecules are tested in large numbers of humans.
We’re at an inflection point in our ability to engineer biology
Several critical developments are now coming together to accelerate the progress of biotechnology exponentially, shifting us to a future where reliable predictive models enable us to engineer complex biological systems quickly and easily instead of relying on today’s brute force strategy of expensive wet lab experimentation. Three fundamental shifts are enabling this: First, advances in AI are making truly predictive models for biology possible; second, the rapidly decreasing cost of running biological experiments to generate data for those models, driven by innovations in lab automation and robotics; and third, our ability to quickly engineer animal and plant cells through technologies like CRISPR.
Deep Learning is now enabling truly predictive models of complex biological systems
Every Noahpinion reader will be familiar with ChatGPT as a blockbuster example of how AI is revolutionizing our world. ChatGPT is a type of deep learning model called a large language model (LLM) that can generate human-like text based on any written prompt. It is a foundation model that is pre-trained and versatile right out of the box and can be applied to diverse tasks like answering questions, summarizing documents, and—our favorite application—writing boring business emails. The evolution of LLMs has been driven primarily by two significant advancements: First, the introduction of transformer technology in 2017 enabled LLMs to process and understand the context of words within large blocks of text, a substantial improvement over earlier models that struggled to capture long-range dependencies; Second, the ability to train these models on large-scale data sets (about 1% of the internet) became possible because of advancements in GPU technology that made this feasible, albeit still very expensive. The resulting model, ChatGPT, seems nothing short of magic, with some users confusing it with general intelligence—but rest assured, it doesn’t know how to do math, physics, or biology.
We have, however, seen success in applying similar approaches to biology. For example, in 2021, Google’s DeepMind released their protein-folding prediction model AlphaFold2, a deep learning model that, like LLMs, is based on transformer architecture. AlphaFold2 can predict the three-dimensional structure of a protein from the RNA sequence encoding it to within 1.5 angstroms of accuracy—on par with high-quality crystallography. While a crystal structure is a static representation of a protein that shifts dynamically between configurations in the cell, it is nonetheless a helpful representation, and AlphaFold predicts this static structure dramatically better than any other protein folding model. This was only possible because of the combination of transformer architecture in a deep learning model trained on a large, expensive data set of 29,000 crystal structures that had been painstakingly collected over decades. This is excellent news for anyone needing information about protein structure, but bad news for the generation of grad students who spent their entire Ph.D. working out the crystal structure of a single protein!
Another excellent example of the predictive power of deep learning in biology comes from MIT, where a team recently used a deep learning model to discover novel antibiotics effective against the superbug MRSA. Their model was trained on an experimental data set of 39,000 compounds, which then allowed the team to computationally screen 12 million compounds and predict which ones were likely to have antimicrobial activity against MRSA. The team took advantage of other AI models to predict the toxicity of the compounds on various human cell types, narrowing down the list to 280 compounds, 2 of which were good candidates for new antibiotics. This is huge—the development of new antibiotics has essentially stalled in recent decades, while antibiotic resistance is one of the most significant threats to human health today. And these are just two of many examples of how AI is now being used to develop truly predictive models in biology.
Lab automation is enabling us to speed up biological data collection to build predictive models
While advances in deep learning are making predictive models possible, these models are only as good as the data they are trained on. And this is where building AI models for biology gets much more complex than building a foundational model for language. While OpenAI could train ChatGPT on a fraction of the internet, one can easily argue that we already have much more biological sequence data. Still, sequence data alone is insufficient because models need outputs like crystal structures or antibiotic efficacy to train on. And while DNA sequencing is now reasonably cheap, most other output data is still outrageously expensive to collect because of the difficulty of conducting biology experiments: you need a highly trained scientist, and costly equipment and consumables, to generate only a modicum of data (hence our joke about a PhD student spending their entire graduate career solving a single protein structure). Luckily, we are also at another inflection point in biology: automation now enables us to run biology experiments with much higher throughput and significantly less manual labor.
We have already moved beyond the early stages of lab automation, where liquid-handling robots outproduced bench scientists by pipetting 96 samples instead of one at a time, toward droplet microfluidics, allowing the scale-down of those reactions to a single drop, increasing throughput to millions of samples from thousands. Today, supported by significant advancements in computer vision, it’s possible to extract massive amounts of data from high-resolution microscopic images of cells, adding another dimension to the available data sets. It’s also possible to use computer vision to train laboratory robots to automate almost anything a scientist can do in the lab, including cell culture. We are also developing new “omics” technologies to measure virtually all the molecular components of the cell, not just DNA. This data collection is further catalyzed by the evolution of laboratory information management systems, versions of which are readily commercially available to capture any data modality a scientist can dream up (and subsequently use to develop the next blockbuster model!). The combination of all of these improvements in lab automation means that we are rapidly increasing the amount (and types) of biological data that can be collected, opening the door for more predictive and accurate models.
We now have the ability to easily edit the DNA of plants and animals, not just simple organisms
In the 1970s, Genentech introduced a single gene into a bacteria to produce HGH recombinantly, and since then, we’ve mastered several relatively simple microbes for use in industrial processes. Today, many essential agricultural products, including amino acids like methionine, lysine, and tryptophan, are made with highly edited microbes in large-scale industrial processes.
The reason we’ve made so much progress in biomanufacturing in microbes is that they are easier to genetically engineer—a scientist can zap in a fragment of DNA into yeast, for example, and it will incorporate that DNA into its genome. This doesn’t work, however, with animal or plant cells. While 90’s technologies such as zinc-finger nucleases and TALENS made it technically possible to edit the DNA of plants and animals, they were complicated and expensive to use, and none of these technologies came close to the potential of CRISPR Cas9. Cas9 is a protein that enables the precise cutting of DNA at a specific location, revolutionizing our ability to gene edit just about anything. It makes advanced genome editing of animal (including human) cells as easy as cloning microbes—and way more straightforward than the early Genetech HGH experiments.
Although the methods to use CRISPR as a gene editing tool were first described in 2012, it takes time for discoveries in fundamental science to translate into industrial applications, and now we are at that point! Last December, the FDA approved the first CRISPR-based human gene editing therapy to cure sickle cell anemia, and there are almost 100 CRISPR clinical trials in the pipeline. While Cas9 was revolutionary, many new CRISPR systems have since been discovered, as well as modifications of the original technology that all contribute to increasing the precision and expanding the number of applications. The technology works on all plant and animal cells, enabling the engineering of everything from crops and livestock to cultivated meat and designer dogs. Our emerging ability to build predictive models of biological systems, and then to change that biology at the genetic level with great precision, is a huge inflection point for humanity.
Biology as an engineering discipline
A foundation model in biology would leverage the unique capabilities of deep learning (and future AI technologies) to efficiently process and model the complex nature of molecular systems. It would integrate massive amounts of data—spanning DNA sequences, RNA levels, protein expression, and environmental factors—to predict all the characteristics of complex systems such as humans or animals. And it would allow us to predict with precision what kind of drugs could best treat a disease or what genetic modifications could reasonably cure it.
Ultimately, we don't know how much data—or what kind of data—is needed to build a foundation model in biology. Are the current datasets like Biobank UK enough, with 500,000 genomes linked with health information and biomarkers? Or do we need to include many more modalities to make it worthwhile? For years, the assumption in AI was that we would need to develop a lot more sophisticated AI models for them to become useful. It turned out that a relatively simple shift to transformer architecture, combined with a lot of data from the internet, was enough to create ChatGPT. The same could be true for biology, which means the right combination of model and data set could be imminent. But regardless of whether it’s tomorrow or years out, it is clear that the combination of AI technology and advancements in automation with easy genetic editing means that we are already at the point where we can engineer biology to an extent never before possible.
For hundreds of years, physicists and chemists have been able to translate a mechanistic understanding of science into real-world use cases, while the immense complexity of biology has made it intensely challenging to translate fundamental scientific discoveries into real-world applications. But now, we stand at the precipice of not just understanding but truly mastering the intricacies of biology. This mastery promises to revolutionize how we approach human health, sustainability, agriculture, and industry, transforming the once elusive realms of biological science into powerful tools that will redefine our capabilities and expand the horizons of human potential.
 | A guest post by
|
 | A guest post by
|
An excellent write up. I particularly appreciate that the authors highlight the revolutions in data analysis and -omics technologies, which are arguably far more important to fundamental progress in biological engineering that CRISPR and other editing technologies are. With that said, I would offer one small criticism (apologies for the long incoming response).
While I broadly agree with the author's and your own optimism regarding the pace and potential of progress within biotech, I do worry that the complexity of biological systems and the resulting difficulty of consistently and accurately engineering them isn't given its proper weight. The model of gene -> mRNA -> protein -> trait is a simplified one that overlooks several other mechanisms and systems of control at each step in the process. It's not just a matter of making more of a transcript to make more of a protein to produce a trait.
It's been known for some time that changes in the level of mRNA transcripts only correlate with protein levels with an R^2 of 0.5 or so (obviously that is an average when looking broadly across different cell types and species). The difference comes about from various processes that determine whether or not a transcript is converted into a protein, like the rate of transcript degradation or the rate of ribosome loading. Additionally, that's only considering the protein coding genes and ignoring the vast number of RNA's that appear to play regulatory roles, the variety of which is so great that I've honestly lost track of all the acronyms that have been invented to categorize that (ncRNA, lncRNA, piwiRNA, siRNA, miRNA, etc.).
Once you actually get the protein produced there are addition levels of control affecting its function. Post-translational modifications, wherein a molecule like phosphate or glucose, is attached to the protein in a way that alters its specificity and/or reaction rate appear to be pretty ubiquitous in the cell and can alter phenotypic traits all on their own. And then of course there's the metabolome, the collection of all the various other metabolites that make up the cell and can alter the rate and direction of metabolic pathways through positive/negative feedback loops. And that's just the stuff we're aware of. I only recently learned of emerging work on a whole 'nother level of control involving tRNA's (the RNA molecules which bring individual amino acids to the ribosome for construction into proteins). Apparently many if not most of the bases of tRNA can be subject to their own modifications, each of which alters the probability that a given tRNA will be involved in protein translation and (presumably) thereby influencing protein production.
None of the above is to say that I'm not optimistic. I am. But it's worth remembering that our efforts to understand biology at a fundamental level have up until very recently been like attempting to understand the engineering principles of an alien supercomputer written in a language we can't understand. Mostly we've just been breaking things and seeing if it produces any interesting or notable effects and even with the emerging revolutions our progress with biology will still involve a fair amount of that trial and error. At least until we have a true mechanistic understanding of how all the interacting components of a cell actually lead to an observed phenotype.
My wife is is biotechnology PhD, and I have been following this domain for the last 13 years or so. I can say that the biotechnology hype is going strong for the last 30 years or so. To me, it's kind of like flying cars, android robots, cold fusion or manned mars exploration. We are told all the time that we are at the tipping point, at the edge of the breakthrough. But it never happens. The hype is pushing more and more young people to study the field, which results in overproduction of graduates with poor career prospects, as well described here: https://goodscience.substack.com/p/texas-gas-stations-nih-sponsored
My wife's graduate program included extra funding from a government program, created based on the government's prediction of high market demand for biotech graduates. After graduation, it turned out that the market demand for biotech graduates was actually very low. The biotech PhD meme pages suggest that the same thing happens all over the world.
I think the biggest gap in these kind of analyses driving the hype is that they are essentially missing the adoption cycle and assuming that all breakthrough technologies are adopted instantly by everyone. This is probably a bias resulting from quick adoption cycles of software and consumer electronics. My experience shows that the typical adoption cycle takes 20-30 years - from the moment the technology first becomes available, to the point it becomes widely adopted by the business and becomes the new standard. For all kinds of technology I worked with - mobile phones, office computers, engineering software such as CAD or FEM analysis, modern data analytics - the business adoption cycle worked that long, and from what I have seen in biotechnology, the adoption cycle seems similar if not longer.