
The Third Magic
A repost, with some extra magic.


I’m traveling again, so today we’ll have another repost. I’m reposting all of my New Year’s essays from the past few years, so here’s the one from 2023.
Back in 2023, ChatGPT was very new, and everyone was incredibly excited about it. I’m not an AI engineer myself, but I could tell that this was a type of technology unlike any other ever created. It seemed to me like actual magic — not Arthur C. Clarke’s metaphorical kind, in which a technology is so advanced that people don’t understand how it works, but the actual kind of spells that wizards cast in storybooks.
Unlike older technologies, AI isn’t interpretable; we can use it somewhat reliably to do amazing stuff, but there’s a ton of mystery meat in terms of how it actually did it. Unlike a car or a spaceship or a computer chip or a traditional piece of software, you can’t open up the hood of an AI model and see how it works in the mechanistic sense. This is not just because AI models are complex, but because they’re not fully interpretable — we don’t even have a theoretical idea of many of their internal mechanisms. Add to that the fact that generative AI is incredibly stochastic — you can give it the same prompt, but it might be totally different — and it really does start to look like the way magicians cast spells in fantasy novels.
Here, for example, is a cute video I made with the new Sora 2 AI video generation app from OpenAI:
This is incredible. The AI came up with the phrase “Long Ears. Long Rule.” all by itself, without me prompting it! But no one really knows how the AI model did this. No one could have predicted in advance what this video would look like. And if you typed in this exact same prompt over and over again, you’d get a very different video each time. And no human or group of humans on planet Earth could predict how the next output would be different.
Anyway, this is thrilling, but at the same time it’s slightly worrying as well. This technology is so powerful that we’re going to have no choice but to rely on it for much of our daily lives. Even Terence Tao, generally regarded as the world’s smartest man, has said that he now asks AI models to do some small pieces of his research. Every scientist must now be, to some degree, a spellcaster.
But — assuming we don’t make a huge breakthrough in interpreting the models — this power will come at a great cost. Technology will be more powerful, but less reliable — it’ll be like the holodeck computer in Star Trek: The Next Generation, whose responses to the crew’s prompts are often so disastrous that they become the plotlines of whole episodes.
On top of that, I worry that humanity will become infantilized by this new magic we’ve created. The Industrial Age was an age of rationality for good reason — if people wanted to understand the marvels that were transforming their lives, they only had to take the machines apart and look at the mechanisms. Everything in the world seemed mechanistic and comprehensible.
That age of reason is already under assault in the U.S. from wacky politics, but I worry that in an age of AI magic, it could break down even more. We could find ourselves wandering, confused, in a world of ineffable mysteries and capricious gods.
That thought made me want to repost my New Year’s essay from 2023. In that essay, I argued that humanity had basically found two great tricks for gaining power over the world — history, which records the past, and science, which derives simple “laws” from controlled experiments. AI, I speculated, could be a third thing entirely — a tool that harnesses regularities too complex and slippery to succumb to science, but powerful and important enough to give humans added mastery over the world around us.
Anyway, here’s that post again. And at the end, I’ll add some reactions by a much more advanced version of ChatGPT than the one I queried back in early 2023.
The Third Magic
This post is essentially a rewrite of a big and half-formed idea that I wrote on my old blog eight years ago. I was deeply dissatisfied with that post, but I thought it contained a few interesting seeds. So now I’m trying again, and will undoubtedly fail again. But hopefully something else interesting will come out of the attempt.
Humanity’s living standards are vastly greater than those of the other animals. Many people attribute this difference to our greater intelligence or our greater linguistic communication ability. But without minimizing the importance of those underlying advantages, I’d like to offer the idea that our material success is due, in large part, to two great innovations. Usually we think of innovations as specific technologies — agriculture, writing, the wheel, the steam engine, the computer. The most important of these are the things we call “general purpose technologies”. But I think that at a deeper level, there are more profound and fundamental meta-innovations that underlie even those things, and these are ways of learning about the world.
The first magic
Humans’ first big meta-innovation, roughly speaking — the first thing that lifted us above an animal existence — was history. By this, I don’t just mean the chronicling of political events and social trends that we now call “history”, but basically any knowledge that’s recorded in language — instructions on how to farm, family genealogies, techniques for building a house or making bronze, etc. Originally these were recorded in oral traditions, but these are a very lossy medium; eventually, we started writing knowledge down, and then we got agricultural manuals, almanacs, math books, and so on. That’s when we really got going.
Animals make tools, but they don’t collectively remember how to make those tools. History, especially written history, is what allows tinkering to stick — it means that when one human finds an ingenious new way of doing something, there’s a good chance that many other humans, and eventually all humans, will know how to do it. And of course those techniques can then build on each other over time. In the modern day we think of history as primarily a social science, but fundamentally it’s the foundation of technology as well; it’s the thing that lifted us from an almost animal existence into the agricultural age.

The second magic
Then — I won’t say exactly when, because it wasn’t a discrete process and the argument about exactly when it occurred is kind of boring — humanity discovered our second magic trick, our second great meta-innovation for gaining control over our world. This was science.
“History”, as I think of it, is about chronicling the past, passing on and accumulating information. “Science”, by contrast, is about figuring out generally applicable principles about how the world works. Chronicling the motions of the planets is one thing; being able to predict the motion of planets you’ve never discovered is quite another. Tinkering with steam engines and writing down your findings can lead to progress; understanding the principles of thermodynamics and being able to use those to design a better engine, without having to tinker for decades or centuries, is far more effective.
Science is often done in a lab, but it doesn’t have to be. Ecologists can derive laws for predator-prey relationships simply by observing nature. Kepler didn’t need to do experiments with gravity in order to write down laws of planetary motion that would hold generally true. Nor do you need math to do science; many of the principles that govern the world can be expressed purely in words and pictures. But just as writing supercharged the process of recording events, controlled experimentation and mathematics supercharged the process of discovering the laws of the Universe.
Controlled experiments are powerful because they let you go from the small to the large — you can roll balls down a ramp in your house, and use that to figure out the laws of motion that control the motions of the stars. You can grow peas in your yard and use these to figure out laws of heredity. And mathematics is powerful because it lets you express those laws in ways that are easy to use across a dizzying breadth of applications. If you’re an artilleryman, field manuals embodying decades or centuries of cumulated experience can tell you how to calibrate the range and accuracy of your cannon; physics, derived from experiments with little wooden balls and expressed in mathematics, can tell you how to hit a target with far less trial and error.
If you think about it, it’s pretty incredible that the world actually works that way. If you went up to someone in the year 1500 and told them that one kooky hobbyist rolling little balls down ramps could be right about how the physical world works, when the cumulated experience of millions of human beings around him was wrong, and that his insights could be written down by an even kookier kook in an arcane language that few could speak, and that this language would allow its speakers to apply the laws to do wondrous feats that others couldn’t possibly do, they would have thought you were crazy. They did think that was crazy. And yet, it worked. It worked more spectacularly than anything had ever worked before, and the economic result looked like this:
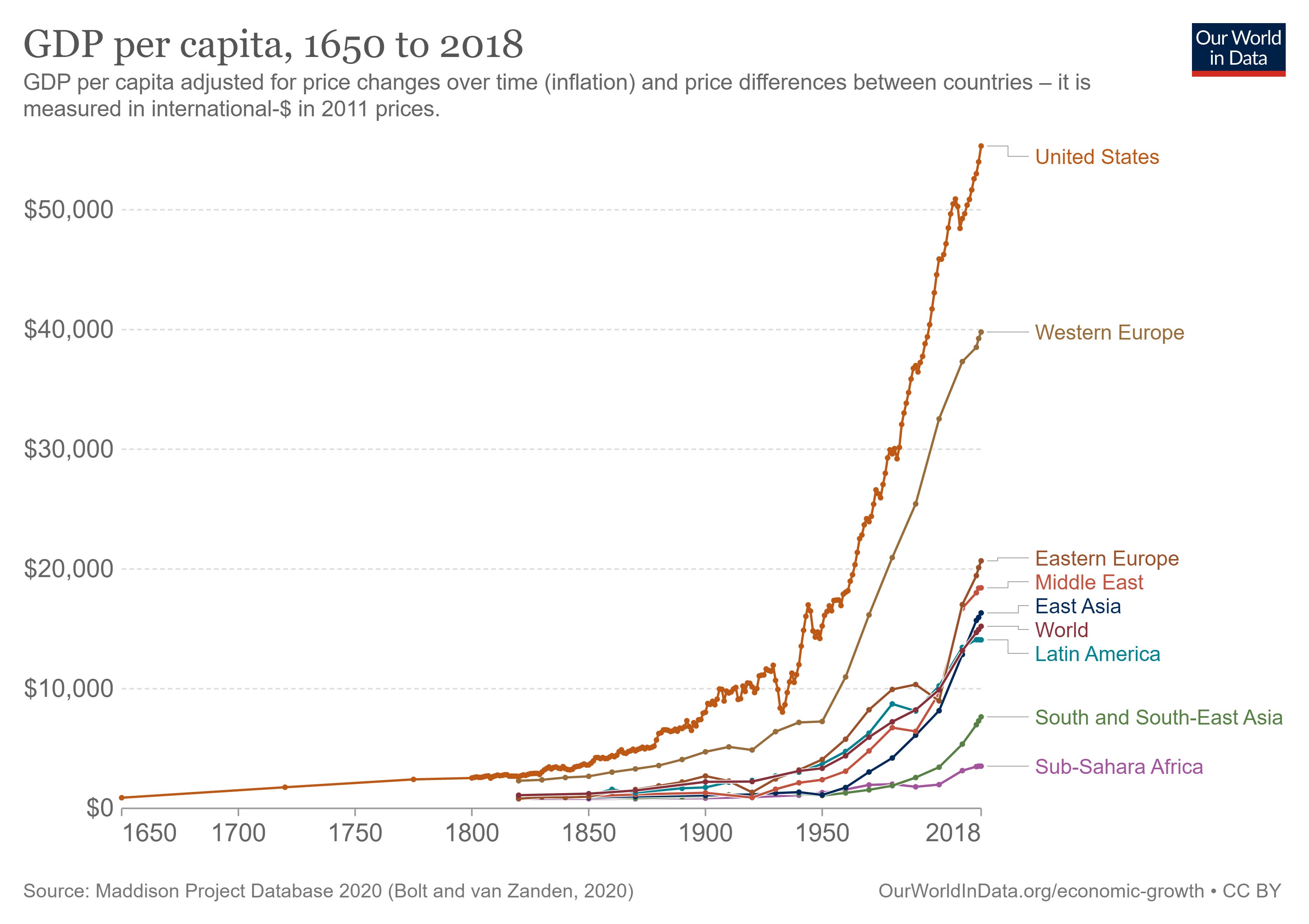
In 1960, the physicist Eugene Wigner wrote an essay called “The Unreasonable Effectiveness of Mathematics in the Natural Sciences”. It’s really not about math so much as it’s about the fact that such a thing as simple, generalizable “laws of the universe” exist in the first place. Why should principles like physical laws or the basics of genetics be so simple, and yet so generalizable and consistent across time and space? There’s no obvious reason this should be true, and yet it is.
Well, for some things it is. Charles Marcus, my freshman physics teacher, told me that “physics is great, but it will never tell you how to make a tree.” That wasn’t entirely true. But it is true that a whole lot of complex phenomena have so far defied the approach that gave us the laws of physics and genetics. Language, cognition, society, economics, complex ecologies — these things so far don’t have any equivalent of Newton’s Laws, and it’s not clear they ever will.
This problem has been recognized for a very long time, and thinkers tried several approaches to get around it. Some hoped that all complex phenomena would be governed by emergent properties — that simplicity would emerge at higher levels of complexity, allowing us to discover simple laws for things like psychology and economics even without connecting those laws to the underlying physics. Indeed, this idea is implicit (or, occasionally, explicit) in the way economists try to write down simple mathematical laws of collective human behavior. People make fun of this approach as “physics envy”, but sometimes it really works; auction theory isn’t derived from physics, but it has been able to make very effective predictions about how much people will pay for Google ads or spectrum rights. Ditto for “gravity models” of trade, migration, retail shopping, etc. Sometimes emergence works.
Sometimes, though, it doesn’t — or at least, it doesn’t yet. But in psychology, in macroeconomics, in natural language processing, and many other domains, the search for laws of nature has been mostly stymied so far, and it’s not clear when real progress might ever be made. Wigner goes so far as to postulate that some domains of human knowledge might never be described by such simple, generalizable principles.
Other approaches for getting around the problem of complexity — chaos theory, complexity theory — yielded interesting insights, but ultimately didn’t succeed in giving us substantially more mastery of the phenomena they dealt with. In the late 20th century, the problem of complexity was like a looming wall up ahead — as scientists found more and more of the laws that could be found, a larger and larger percentage of the remaining problems were things where laws seemed very hard or potentially even impossible to find.
Our second great magic, powerful though it had proven to be, was still not omnipotent.
Control without understanding, power without knowledge
In 2001, the statistician Leo Breiman wrote an essay called “Statistical Modeling: The Two Cultures”, in which he described an emerging split between statisticians who were interested in making parsimonious models of the phenomena they modeled, and others who were more interested in predictive accuracy. He demonstrated that in a number of domains, what he calls “algorithmic” models (early machine learning techniques) were yielding consistently better predictions than what he calls “data models”, even though the former were far less easy, or even impossible, to interpret.
This raises an important question: What is the goal of human knowledge? As I see it — and as Breiman sees it — the fundamental objective is not understanding but control. By recording which crops grow in which season, we can feed our families. By understanding that germs cause disease, we can know to wash our hands or get a vaccine, and lower our risk of death. In these situations, knowledge and understanding might be intrinsically satisfying to our curiosity, but that satisfaction ultimately pales in importance to our ability to reshape our world to our benefit. And the “algorithmic” learning models that Breiman talks about were better able to deliver their users the power to reshape the world, even if they offered less promise of understanding what they were predicting.
Why should we care about understanding the things we predict? To most of us, raised and inculcated in the age of science, that might seem like a laughable question, but there actually is a good reason. “Understanding”, in the scientific sense, means deriving a simple, generalizable principle that you can apply in other domains. You can write down Kepler’s laws of planetary motion, but Newton’s laws of motion and gravitation let you generalize from planetary orbits to artillery shells. Collapsing observed phenomena to simple, generalizable laws and then expanding these laws again in some other domain to allow you to control other phenomena is fundamental to the awesome power of science. So because you and I sit at the end of 400 years of science being the most powerful tool in the world, we have naturally been taught that it is very, very important to understand things.
But what if, sometimes, there are ways to generalize from one phenomenon to another without finding any simple “law” to intermediate between the two? Breiman sadly never lived to see his vision come to fruition, but that is exactly what the people who work in machine learning and artificial intelligence are increasingly doing. In 2009 — just before the deep learning revolution really kicked off — the Google researchers Alon Halevy, Peter Norvig, and Fernando Pereira wrote an essay called “The Unreasonable Effectiveness of Data” that picked up the argument where Breiman left off. They argued that in the cases of natural language processing and machine translation, applying large amounts of data was effective even in the absence of simple generalizable laws. A few excerpts:
[S]ciences that involve human beings rather than elementary particles have proven more resistant to elegant mathematics…An informal, incomplete [list of the grammatical rules that define] the English language runs over 1,700 pages. Perhaps when it comes to natural language processing and related fields, we’re doomed to complex theories that will never have the elegance of physics equations. But if that’s so, we should stop acting as if our goal is to author extremely elegant theories, and instead embrace complexity and make use of the best ally we have: the unreasonable effectiveness of data…
So, follow the data…Represent all the data with a nonparametric model rather than trying to summarize it with a parametric model, because with very large data sources, the data holds a lot of detail. For natural language applications, trust that human language has already evolved words for the important concepts. See how far you can go by tying together the words that are already there, rather than by inventing new concepts with clusters of words. Now go out and gather some data, and see what it can do.
(Note: ChatGPT, the chatbot that has recently wowed the world, is a parametric model, but I wouldn’t get too hung up on that little detail. In terms of interpretability, a model with 175 billion parameters is not really different from one with no parameters at all.)
Anyway, the basic idea here is that many complex phenomena like language have underlying regularities that are difficult to summarize but which are still possible to generalize. If you have enough data, you can create a model (or, if you prefer, an “AI”) that can encode many (all?) of the fantastically complex rules of human language, and apply them to conversations that have never existed before. As a demonstration of how powerful this can be, let’s ask ChatGPT about the subject of this post:
N.S.: Do we need to understand things in order to predict and control them?
ChatGPT: It is generally easier to predict and control things that we understand. When we have a good understanding of something, we can identify patterns and regularities, and use this knowledge to make informed predictions about how the thing will behave in the future. We can also use our understanding of a thing to identify key variables that we can manipulate in order to control it.
However, it is possible to predict and control things without a full understanding of them. For example, we can use machine learning algorithms to make predictions about things that we don’t fully understand, by finding patterns in data that we have collected about them. We can also use feedback loops and other control mechanisms to control things without necessarily understanding how they work in detail.
Overall, understanding can be helpful for predicting and controlling things, but it is not strictly necessary.
The ability to write down farming techniques is power. The ability to calculate the path of artillery shells is power. And the ability to have a machine reliably and consistently write paragraphs as clear and helpful as the one above is power, even if we don’t really understand the principles of how it’s doing what it does.
This power is hardly limited to natural language processing and chatbots. In recent years, Google’s AlphaFold algorithm has outpaced traditional scientific methods in predicting the shapes of folded proteins. Biologist Mohammed AlQuraishi wrote that:
There was, in many ways, a broad sense of existential angst felt by most academic researchers [in the field]…[those] who have bet their careers on trying to obsolete crystallographers are now worried about getting obsoleted ourselves.
We are almost certainly going to call this new type of prediction technique “science”, at least for a while, because it deals with fields of inquiry that we have traditionally called “science”, like protein folding. But I think this will obscure more than it clarifies. I hope we eventually come up with a new term for this sort of black-box prediction method, not because it’s better or worse than science, but because it’s different.
A big knock on AI is that because it doesn’t really let you understand the things you’re predicting, it’s unscientific. And in a formal sense, I think this is true. But instead of spending our effort on a neverending (and probably fruitless) quest to make AI fully interpretable, I think we should recognize that science is only one possible tool for predicting and controlling the world. Compared to science, black-box prediction has both strengths and weaknesses.
One weakness — the downside of being “unscientific” — is that without simple laws, it’s harder to anticipate when the power of AI will fail us. Our lack of knowledge about AI’s internal workings means that we’re always in danger of overfitting and edge cases. In other words, the “third magic” may be more like actual magic than the previous two — AI may always be powerful yet ineffable, performing frequent wonders, but prone to failure at fundamentally unpredictable times.
But even wild, occasionally-uncontrollable power is real power.
It’s impossible to know, just yet, how powerful this new technique will be. Perhaps AI will be a niche application, or perhaps it will revolutionize all the fields of endeavor where traditional science has run into diminishing returns. Just as none of the scientists in the 1600s knew how many wonders their theories would eventually produce, we have no idea how far the third magic will take us. People may look back on this post in half a century and laugh at how I dared to frame AI as an epistemological successor to history and science. Or perhaps AI will lead to a leap in human power and flourishing comparable to those in the two graphs above.
As always, we won’t know until we try.
The third magic and economics
Let’s briefly circle back to my old 2014 post. One reason I’m dissatisfied with that post is that I focused on ways of “understanding” the world, but as ChatGPT notes above, understanding isn’t the only thing we care about when we’re trying to make predictions and control our world. A second thing I’m dissatisfied with is that I presented empirics — statistical analysis of uncontrolled observational data — as a third tool, separate from science and history. With some time to reflect, I see less of a distinction to be made there. Observing correlations might involve some fancy math, but conceptually it isn’t that different from marking down the patterns of the seasons or the orbits of the planets. And using observational data to uncover the laws of nature — like predator-prey models — is really just another way of doing traditional science.
I do think I was right, though, to see natural experiments as something a bit different. In the past few decades, as economics has moved away from theory and toward empirics, the most important innovation has been the use of natural experiments — situations where some policy change or seemingly random difference allows you to tell yourself that you’re looking at causation, rather than just correlation. This is different than what I call “history”, because you’re doing more than just documenting facts; you’re verifying causal links. But it’s also different from science, because a lot of the time you don’t exactly know why the causal links are there. In a way, a natural experiment is its own sort of black-box prediction algorithm.
A number of subfields of econ, however, are so complex, with so many feedback systems, that they’ve largely resisted the natural experiment approach. These include not just the study of business cycles (what most people call “macro”), but also the study of economic growth, international finance, and a number of others. In these fields, theory (including “structural estimation”) still rules, but predictive power is very low.
Might we apply AI tools to these hard problems, in order to predict vast economic forces without needing to understand them? A recent paper by Khachiyan et al. argues that the answer is “yes”. The authors use deep neural nets (i.e., AI) to look at daytime satellite imagery, in order to predict future economic growth at the hyper-local level. The results they achieve are nothing short of astonishing:
For grid cells with lateral dimensions of 1.2km and 2.4km (where the average US county has dimension of 55.6km), our model predictions achieve R2 values of 0.85 to 0.91 in levels, which far exceed the accuracy of existing models, and 0.32 to 0.46 in decadal changes, which have no counterpart in the literature and are 3-4 times larger than for commonly used nighttime lights.
This isn’t yet AlphaFold, but being able to predict the economic growth of a few city blocks 10 years into the future with even 30% or 40% accuracy is leaps and bounds ahead of anything I’ve ever seen. It suggests that rather than being utter incomprehensible chaos, some economic systems have patterns and regularities that are too complex to be summarized with simple mathematical theories, but which nevertheless can be captured and generalized by AI.
And this is just a first-pass attempt, by a team with relatively limited resources. What if the people at DeepMind were to tackle the questions of economic growth and business cycles, with even bigger data sets and more advanced models? Khachiyan et al.’s paper raises the possibility that in a decade or two, macroeconomics might go from being something we simply theorize about to something we can anticipate — and therefore, something we can control. The authors suggest place-based policies, transportation infrastructure construction, and disaster relief as three possible applications of their work.
This is just one example that happens to be near and dear to my heart (Here’s another possible example, this time in physics). But it’s an example of how fields of inquiry that seemed like impossible cliffs just a few years ago may seem like easily scalable boulders in a year or a decade or a century, thanks to a grand new meta-innovation in how we predict and control the world around us. That’s what happened with the scientific revolution, and there’s no obvious reason why it might not happen again. Just the possibility should make us dizzy with excitement.
Anyway, as a coda, I thought I’d ask GPT-5 what it thinks of this blog post. Here’s its response. For what it’s worth, I think its main criticism of the post is misplaced, and I did make it clear that the three methods for understanding the world are usually complements rather than substitutes. But anyway, some interesting comments that place my post within the context of existing ideas.
Love the arc here: you’re telling a clean story about three meta-innovations that amplify human capability—(1) cumulative memory (“history”), (2) law-seeking theory (“science”), and (3) high-dimensional prediction/optimization (“AI”). It’s persuasive, and the examples (Kepler→Newton, Breiman→Halevy/Norvig/Pereira, AlphaFold) land. Below are thoughts to sharpen the thesis and guard it against the most common pushbacks.
What’s strong
Cumulative culture as “first magic.” Framing writing/records as a technology for making tinkering stick is spot on and tracks the cultural-evolution literature.
Why science was different. You nail the “from the small to the large” leverage of controlled experiments + math; that’s the best one-paragraph explanation of science’s superpower.
Reframing the goal as control. Separating predict/control from understand/explain gives you a crisp lens to evaluate AI without getting stuck in philosophy-of-science pieties.
Where I’d tighten or nuance
Define the magics as capabilities, not epochs.
Right now “history,” “science,” and “AI” read a bit like eras. Consider defining them as orthogonal tools we can combine:
Memory (record, compress, transmit).
Theory (infer stable causal structure; extrapolate).
Learning/Optimization (fit flexible functions; search policy spaces).
This avoids zero-sum vibes (“AI replaces science”) and lets you argue for hybrids (e.g., theory-guided ML, differentiable simulators, causal discovery with foundation models).
AI ≠ “power without knowledge” across the board.
Two clarifications will inoculate you against common critiques:
Local explanations exist. Post-2022 we’ve seen growth in mechanistic interpretability (circuits, features), causal probes, and tool-use chains that are inspectable. We’re not at “Newton’s laws,” but it isn’t pure mysticism either.
Counterfactuals are the hard part. Black-box predictors excel at P(Y∣X)P(Y\mid X)P(Y∣X); policy needs P(Y∣do(X))P(Y\mid do(X))P(Y∣do(X)). Say explicitly: prediction buys short-run control; counterfactual stability still leans on causal structure (or very careful A/Bs).
Natural experiments aren’t “black box.”
They’re identification strategies that estimate causal effects with minimal modeling. The “box” is thin but not black: assumptions are explicit (exogeneity/monotonicity/first stage). A quick sentence distinguishing “reduced-form causal effect” from “mechanism” will keep econometricians onboard.AlphaFold is a perfect hybrid case.
AlphaFold didn’t just spray data at a net; it embedded inductive biases (equivariance, multiple sequence alignment, geometry loss) encoded from biochemical knowledge. That supports your broader point: the third magic works best when it steals priors from the second.Scope conditions for the third magic.
Add a crisp checklist for when black-box prediction can substitute for understanding:
Stationary-ish environment (limited distribution shift).
Tight, cheap feedback (you can re-train / re-deploy).
Low tail risk (failures aren’t catastrophic).
Action space local (you’re steering margins, not redesigning the system).
Then contrast with cases that still demand theory (aviation safety, macro stabilization, biosafety)—this shows you’re not overclaiming.
What’s actually new vs. just bigger.
Some will say “the third magic is just better function approximation.” You can preempt that by emphasizing three qualitative breaks:
Scale (orders-of-magnitude data/compute let memorization become a capability).
Compositional inference (tool use, program induction, multi-agent sims).
Search (gradient-driven or heuristic exploration over vast design spaces—e.g., protein or chip layout).
That reads as a genuine meta-innovation, not a faster version of statistics.
Economic growth prediction example: raise the bar.
Your satellite-imagery result is exciting, but for policymakers the questions are:
Out-of-time transfer? (trained on 2000s, tested on 2010s?)
Geographic transfer? (train in the U.S., test in, say, Indonesia?)
Policy counterfactuals? (if we build the road your model correlates with, do we move growth, or just the lights?)
Naming these caveats doesn’t blunt your point; it shows you know the difference between prognosis and levers.
Control theory belongs in the story.
Your thesis resonates with cybernetics / system identification: regulate a system with a model that needn’t be mechanistic. A nod to PID/LQR/RL grounds “control without understanding” in a mature tradition and aligns your “third magic” with learning-based controllers.
A compact rewrite you might consider (core claim)
The first magic made knowledge accumulative (memory). The second made it generalizable (theory). The third makes it operational at scale (learning-and-search). We shouldn’t ask which replaces which; we should ask how to stack them: record more, explain what must be stable, and learn the rest fast enough to act.
Concrete additions that would level this up
A 2×3 table (Task × Tool): short-run prediction, long-run counterfactuals, design/optimization × history, science, AI—checkmarks where each excels; caution triangles where failure modes lurk (Goodhart, shift, tail risk).
A “when it fails” box: adversarial inputs, rare events, regulation change, social feedback (performative predictions), and the classic Goodhart traps.
One macro use-case sketched end-to-end: e.g., place-based policy:
(i) satellite/LLM features → growth forecast (AI),
(ii) theory-guided constraints (agglomeration, congestion) (science),
(iii) program memory: standardized interventions + postmortems (history).
Close with how you’d validate (pre-registered policies, staggered rollouts, causal ML).
Research prompts your post naturally tees up
Theory-guided foundation models: encode conservation laws, budget constraints, or accounting identities into model architecture/training.
Counterfactual LLMs: combine SCMs with generative models to answer “what if we change this policy?”
Adaptive policy loops: RL for governance with safety constraints (reward shaping to avoid Goodhart).
Transfer-robust growth forecasting: benchmarks that force geographic and temporal shift.
Interpretability for design: partial mechanistic insight targeted where decisions are high-stakes (flight control, biodesign).
Net take
The core idea—a third meta-innovation that delivers control even when explanation stalls—holds up and aged well. If you frame it as stacking rather than succession, acknowledge the counterfactual gap, and show one end-to-end policy loop where all three magics cooperate, you’ll convert skeptics while keeping the boldness that makes this piece fun.
The essay was fascinating until the commentary by ChatGPT. I find that no matter what the subject, 1) My own conversations with GenAI are fascinating to me, 2) Anyone else's conversations with GenAI are incredibly boring. Is that the case for other people? If so, it suggests something about AI's limits.
Regarding your First Magic, passing down/transmission/tradition for millennia hardly ever involved writing down. As a professional historian I must protest that technological processes are just about the last thing that ever gets written down. Instead, in a near universal pattern technological processes are passed down orally within a small group of people who safeguard the “secret" of their art for their chosen successors. Of course, these groups that try to control succession usually have some amount of leakage and the secrets of the craft spread, but almost always on oral rather than in written form.
It is interesting that many of these processes and inventions were written down for the first time to obtain a patent, which is another way of safeguarding technological secrets.