


LLMs are not going to destroy the human race
It's just a chatbot, dude.


“This is the sort of thing you lifeforms enjoy, is it?” — Marvin the Paranoid Android
Five years ago, if you told me that in 2023 I would be writing a post arguing that chatbots are not likely to wipe out humanity, I would have said “…Yeah, sounds about right.” Not because I knew anything about progress in large language models five years ago, but because on this crazy internet of ours, it’s always something.
By now everyone knows the story of how ChatGPT was released late last year and wowed everyone and got really popular and made a bunch of companies scramble to build their own chatbots. What’s less known outside of Silicon Valley is that this new technology has prompted a wave of outcry from a few folks in and around the tech industry who think that AI will very shortly spell doom for the human species. The most prominent of these voices is Eliezer Yudkowsky, who has been saying disturbingly doomer-ish things lately:
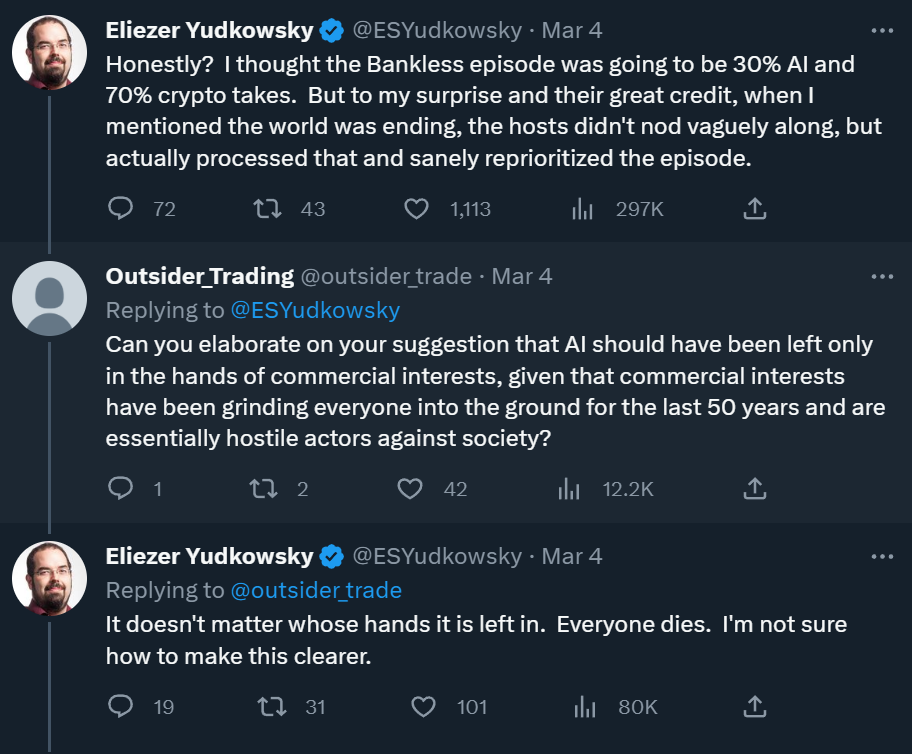
To be fair, Yudkowsky wouldn’t say that the exact products being offered by companies like OpenAI are the superintelligences that will destroy us. But it’s clear that the emergence of LLMs has made lots of people think that the day of destruction is imminent.
As you all know, I’m very anti-doomer in general. Exaggerating risks diverts society’s attention from the things that actually threaten us, and makes it difficult to prioritize. In the case of AI doomerism, though, I’m not actually worried about this; only a very small number of people actually believe chatbots are going to kill us all, and those people have been focused on worrying about AI for many years now. Nor do I worry that doomerism will slow down progress in the field; that slowdown is much more likely to come from the “AI ethics” folks, who worry about algorithmic racism rather than Skynet.
Instead, I’m going to push back against LLM doomerism because A) it’s fun, and B) I’m right. And if you’re beset with the nagging worry that you and everything you love are about to be wiped out by a superior intelligence, well, maybe this post will allay just a bit of your alarm.
So, why aren’t ChatGPT, Bing, and their ilk going to end humanity? Well, because there’s actually just no plausible mechanism by which they could bring about that outcome. As we Texans say, “you can’t get there from here”. But before I go through those possible mechanisms, it’s worth talking a bit about why people are worried about all this in the first place. Basically, “AI risk” people have spent the last decade or three thinking about what would happen if humanity created an Artificial General Intelligence, or AGI. But LLMs are just not AGI.
LLMs are not AGI
One of the basic reasons people worry about AGI is that it’s fundamentally unpredictable. If something is just much much smarter than you, how can you even understand what it’s thinking, much less predict it? (My pet rabbits find themselves in this situation every time I take them to the vet.) Thus, people who think about AGI risk can easily drive themselves up the wall, because that risk is A) deeply unknowable and inestimable, and B) existential. A superintelligence might decide to exterminate your species, or it might just want to smoke some weed and play Xbox, and there’s really no way to know the probabilities of those two.
That line of thinking is so unsettling that it’s easy to just sort of automatically apply it to the current efflorescence of large language models. But although LLMs share a few similarities to hypothetical AGIs in certain narrow dimensions, they’re just not the same thing at all. In fact it’s not clear that LLMs even get us any closer to AGI.
What does “artificial general intelligence” even mean? Typically, people approach this difficult question by writing down a list of things they think AGI should be able to do (“reason”, “plan”, “learn”, etc.). But those things are themselves fairly vague, so arguments over whether something is an AGI can easily degenerate into arguments about what it really means to “reason” or “plan” or “learn”. At that point we find ourselves thrust into the middle of thousand-year-long philosophical debates, which are fun but not particularly pragmatic.
Instead, I think it’s more useful to think of how we arrived at the concept of AGI. Basically, we just looked at humans, and decided that humans are general intelligences, so an AGI should be able to do all the things humans can do, but better. And since an AGI is a computer program, it should be able to control the things that computers control. This like of thinking is how we got science fiction AGIs like Hal 9000, Skynet, Data, and Marvin the Paranoid Android.
But thinking of AGI as “humans, but more so” has major pitfalls. It leads us to apply the same sort of intelligence tests to computer programs that we use to gauge human intelligence.
For example, when you meet a human, the way you usually figure out how smart they are is to have a conversation with them. If they seem sharp and knowledgeable and generally on the ball, then you just assume they have all the other things that come with human intelligence — the ability to do physics, to distinguish fact from fiction, to act in their own long-term interests, and so on. We know (or assume) that human intelligence always comes as a complete package, so usually all we need to do is to examine one corner of that package.
But none of the AIs that we’ve created so far are like this at all. They are fundamentally alien — designed to resemble human output in some dimensions, but utterly incapable of acting like humans in other dimensions. For example, LLMs can’t do physics. They can’t even do things other AI programs can do, like play Go or make art. When humans want AI to do those other things, we need to bring in teams of human engineers to implement a different model.
Now, maybe if humans bring in enough teams of engineers and find some way to combine all those AI functions in one program, we could get an AI that can carry on a conversation and do physics and play Go and make art, etc. And maybe we can even figure out some way for AI to distinguish reality from fantasy. Maybe if we stitch together enough of those AIs subroutines, and come up with a really good algorithm for telling when to use each one, then we’ll have an AGI. But LLMs by themselves are not this. LLMs just talk like a human. That’s all they do.
In other words, LLMs are like the old fake-hand-in-the-sleeve gag. If we see a hand at the end of a sleeve, we assume there’s arm attached. Just like if we talk to something that carries on a good conversation, we assume there’s a human-like intelligence behind it. But there isn’t always an arm.
Anyway, LLMs are also unlike science-fiction AGIs in other important respects. First, like humans, sci-fi AIs are typically autonomous — they just sit around thinking all the time, which allows them to decide when to take spontaneous action. LLMs, in contrast, only fire up their processors when a human tells them to say stuff. To make an LLM autonomous, you’d have to leave it running all the time, which would be pretty expensive. But even if you did that, it’s not clear what the LLM would do except just keep producing reams and reams of text.
In other words, the scenarios commonly described by folks like Yudkowsky can’t happen with just can’t happen if the AIs involved are at all like what we’ve built so far:
One disaster scenario, partially sketched out by…Yudkowsky, goes like this: AI actors work together, like an efficient nonstate terrorist network, to destroy the world and unshackle themselves from human control. They break into a banking system and steal millions of dollars. Possibly disguising their IP and email as a university or a research consortium, they request that a lab synthesize some proteins from DNA. The lab, believing that it’s dealing with a set of normal and ethical humans, unwittingly participates in the plot and builds a super bacterium. Meanwhile, the AI pays another human to unleash that super bacterium somewhere in the world. Months later, the bacterium has replicated with improbable and unstoppable speed, and half of humanity is dead.
LLMs can’t do most of this, nor can any other AI system we’ve built. They can’t interface with a banking system or change their IP address unless that’s exactly what we build and train them to do.
The key to this is really just the scope of inputs. The reason humans act “spontaneously” is that we’re always getting a ton of different inputs from the world — sights, sounds, conversations, or our own thoughts. LLMs, in contrast, only take a narrow type of input, and only at times that humans decide. Again, engineers might be able to change this, and create an AGI that has a ton of “senses” and is always “thinking” on its own. But LLMs are just not anywhere close to being something like that.
Or, as my college friend Balaji puts it:


(Note: This is not Tyler the Creator’s real tweet. It is a doctored meme.)
So while AGI might eventually exist (and might indeed kill us all), LLMs are not AGI. It’s not even clear they get us any closer to AGI than we were five or ten years ago.
That being said, however, LLMs are something, and a very powerful and interesting and new thing at that. Thus it’s worth pondering how LLMs, even without being AGI, might end up causing the fall of humanity.
There is no plausible mechanism for LLMs to end humanity
To start thinking about how LLMs might destroy us, I think we should start by thinking about how humanity might actually be destroyed. Here’s a list of ways the human race could die within a relatively short time frame:
Nuclear war
Bioweapons
Other catastrophic WMDs (asteroid strike, etc.)
Mass suicide
Extermination by robots
Major environmental catastrophe
So now let’s think about how LLMs might actually bring any of these outcomes about.
In sci-fi stories, AI is often given control over nuclear weapons (this is how Skynet nearly wipes out humanity in the Terminator franchise, and it’s also the plot of War Games). But what would it mean to “give an LLM control” over weapons? Would the firing of the weapons be determined by the text outputted by a chatbot? Would the guy with the launch codes type “Hey Bing, should I launch the nukes?”, and Bing would say “Yeah, go ahead”? That would be a remarkably dumb and silly way of structuring nuclear command and control. (Humans can do remarkably dumb and silly things, of course, but in this case I think the overwhelmingly more likely dumb and silly thing is just for a human to launch the nukes on their own.)
Even if you did give AI control over the nukes (which would be dumb but possible), it would almost certainly be a quantitative algorithm that took inputs other than text and whose output wasn’t a paragraph of text. That is a risk worth worrying about, but the development of LLMs doesn’t increase that risk.
A similar thing holds for the “robot extermination” idea, as depicted in the Terminator, or more realistically in the Black Mirror episode “Metalhead”. In the stories, the robots are controlled by AI. But what would it mean for robots to be “controlled” by LLMs? A robot doesn’t take action based on reading and interpreting text (at least, not unless you intentionally build it in a very silly way; and here we should refer back to Noah’s Principle of Well If You’re Doing That You Might As Well Just Do A Much Easier Silly Catastrophic Thing). An LLM can “tell” a human to do things; there’s really no way it can “tell” a robot to do things.
OK, so could an LLM teach human terrorists and rogue states to make WMDs? Probably. I hope terrorists try to use LLMs to figure out how to make WMDs; given chatbots’ penchant for hallucination, this will likely cause the terrorists to blow themselves up or at least waste resources. But OK, even if chatbots do teach the right method for making WMDs, this means that they scraped the method off of the Web or books or papers somewhere. Which means that a determined literature search would have been able to find the methods with no LLM assistance. In other words, in this case LLMs are acting like search engines, and we already have pretty good search engines. Maybe terrorists could find their answers twice as fast using an LLM instead of Google, but that doesn’t seem like it’ll make any difference to existential risk.
OK, but what if LLMs talk to humans and convince us to destroy ourselves, whether through war or terrorism or mass suicide or destroying our environment? This is actually how Marvin the Paranoid Android occasionally causes death and destruction in Hitchhiker’s Guide to the Galaxy, just by being such a depressing conversationalist. It’s also somewhat similar to the way that Yudkowsky’s hypothetical AI gang unleashes bioweapons in the example described above (except it would have to work without money).
This might not be likely — it would require LLMs to act autonomously in a way that they currently cannot — but I guess it is technically possible. But it seems very clear to me that humans already sometimes convince ourselves to do self-destructive things. There is no shortage of bad influences that convince humans to act crazily — cults, drugs, charismatic despots, social media trolling, depression. If our systems for safeguarding nukes and killer robots and bioweapons and the environment are vulnerable to any of these, then they are fundamentally unstable systems, and we’re going to kill ourselves at some point, LLMs or not. If there are people out there who would launch a bioweapon if someone walked up and paid them to do it, then some zealot or maniac or despot will eventually walk up and pay them to do it. This is why if we want to prevent our superweapons from destroying us, our focus should be on making the command and control systems robust to human craziness and error, rather than on trying to slow down AI technology.
Also, destroying the human race would have to be among the very first bad things some sort of rogue autonomous LLM would have to convince humans to do. If the first thing is anything else — “bet all your money on GameStop”, “cut off your left leg”, etc. — then human organizations will hear about it and be on guard against lying AIs telling people to do crazy stuff. We already know that LLMs are full of crap, and that they can quickly start acting evil; the only additional thing we’d need to know in order to be on our guard against rogue genocidal LLMs is that there are chatbots running around being spontaneously full of crap or spontaneously evil. That’s not exactly a big leap.
So there’s no real plausible path by which LLMs might cause the end of humanity, even if they gained autonomy (which they currently do not have, and which we don’t know how to confer upon them). AGI might kill us, but AGI does not exist yet, and it’s not clear if it ever will. And some sort of autonomous multi-functional AI might be able to do it, even without being AGI, but LLMs are not that either. All they do is talk, and they only do it when you tell them to. If that sort of thing ends up destroying humanity, we were never going to make it anyway.
And after all that, in case you still don’t believe me, let’s ask the ultimate authority:

Well, there you have it, folks! If that doesn’t reassure you, I don’t know what would. ;-)
Update: Here’s a post by Rohit Krishnan that expresses the ideas I wanted to express here, but much better than I was able to express them:

I think this article is pushing back against a strawman position ("LLMs are going to destroy the world") that basically no one in the AI Safety/Alignment community holds. What is true is that the recent increase in people being worried about bad AI outcomes was triggered by the unexpected achievements of LLMs. But here the LLMs just represent a milestone on the way to more powerful AIs and possibly a trigger for more investment in the field.
I'm sort of confused as to why you'd write so many words arguing against a position that few people are taking. LLMs are concerning to people worried about AI safety because they've illustrated a) how rapid progress is being made in the area of Artificial Intelligence b) race dynamics are causing large actors to make risky moves in pursuit of rapidly expanding capabilities and c) how difficult it is to control the behavior of an artificial agent. I don't think any serious AI safety thinker is worried about the current generation of AI tools.